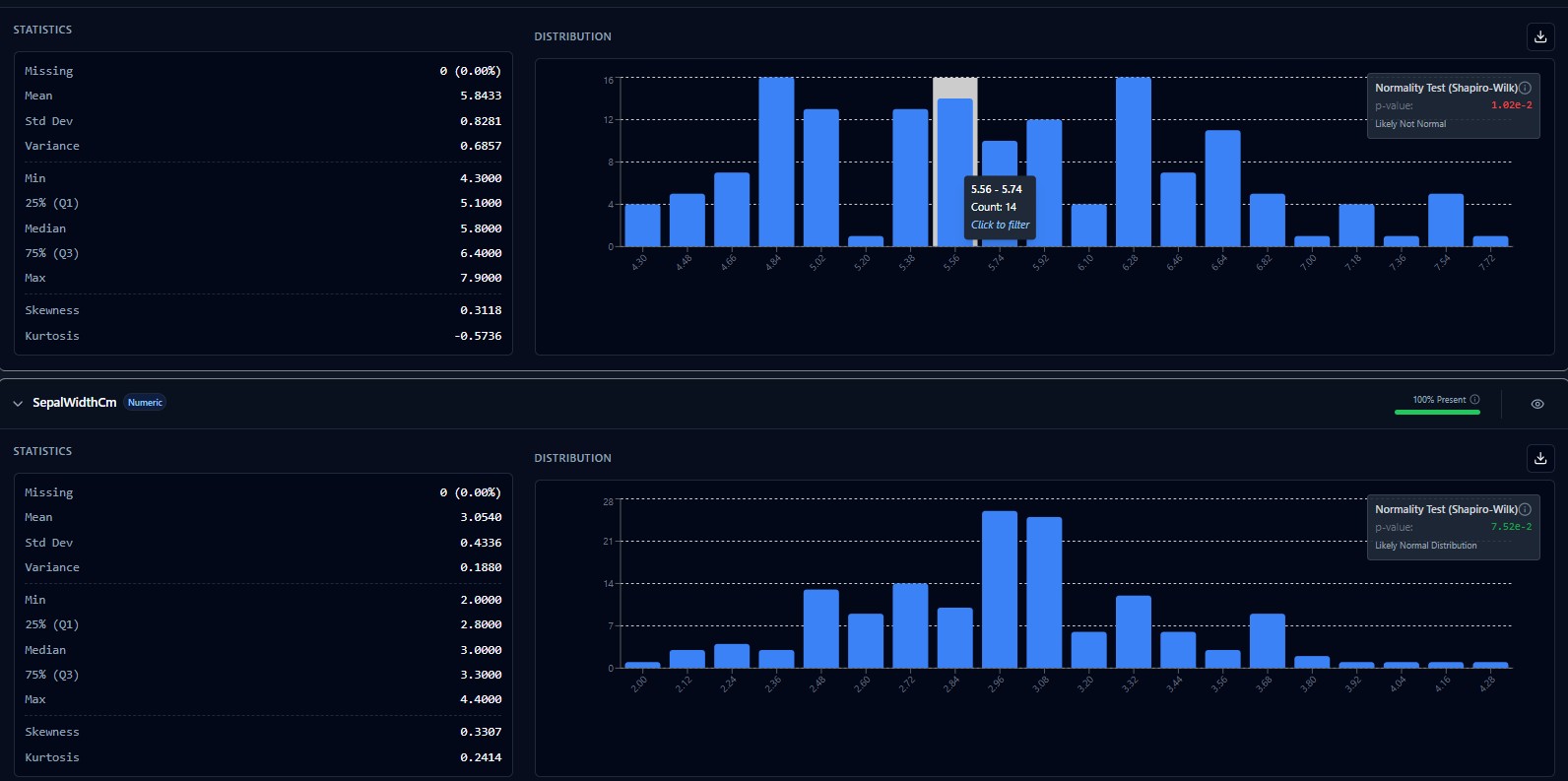
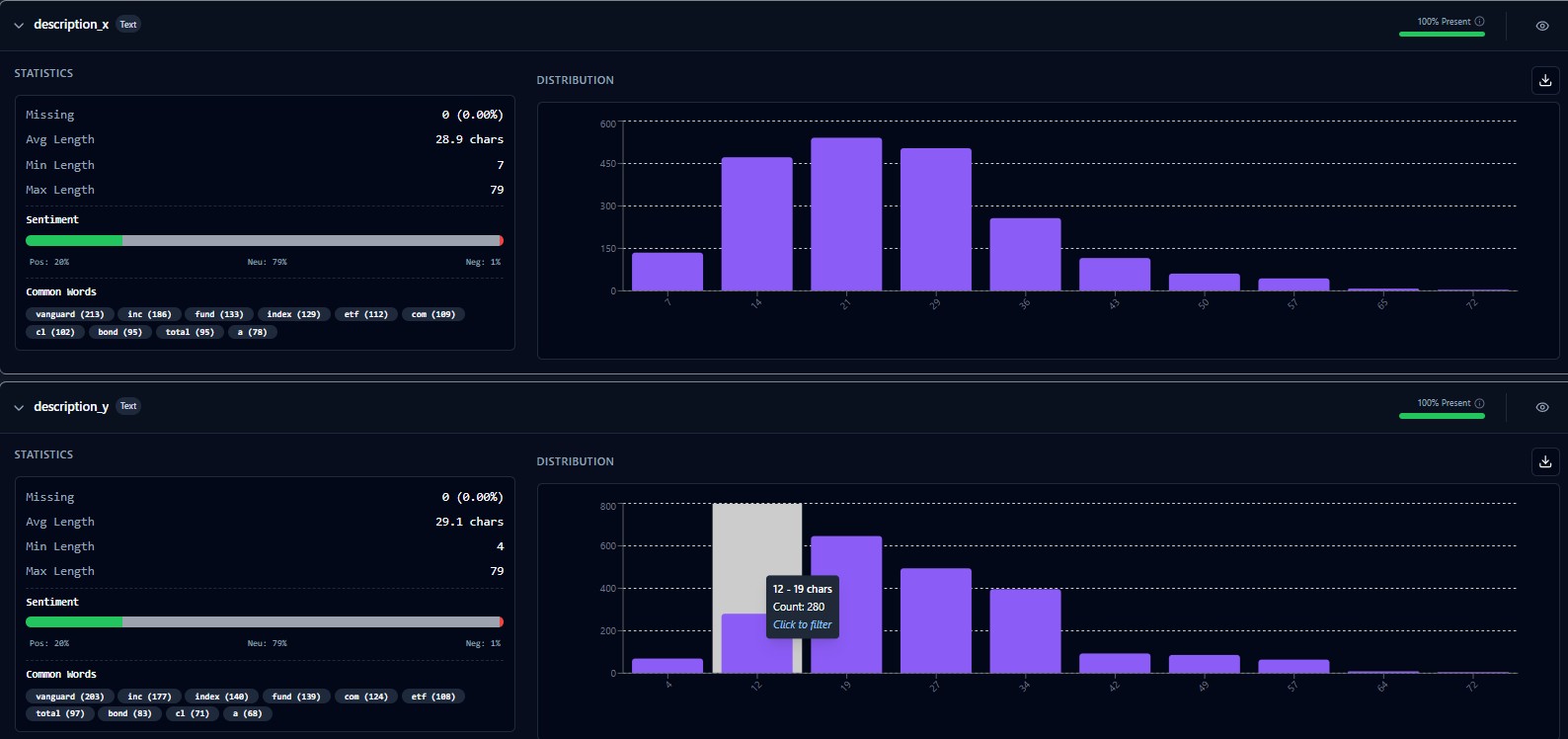
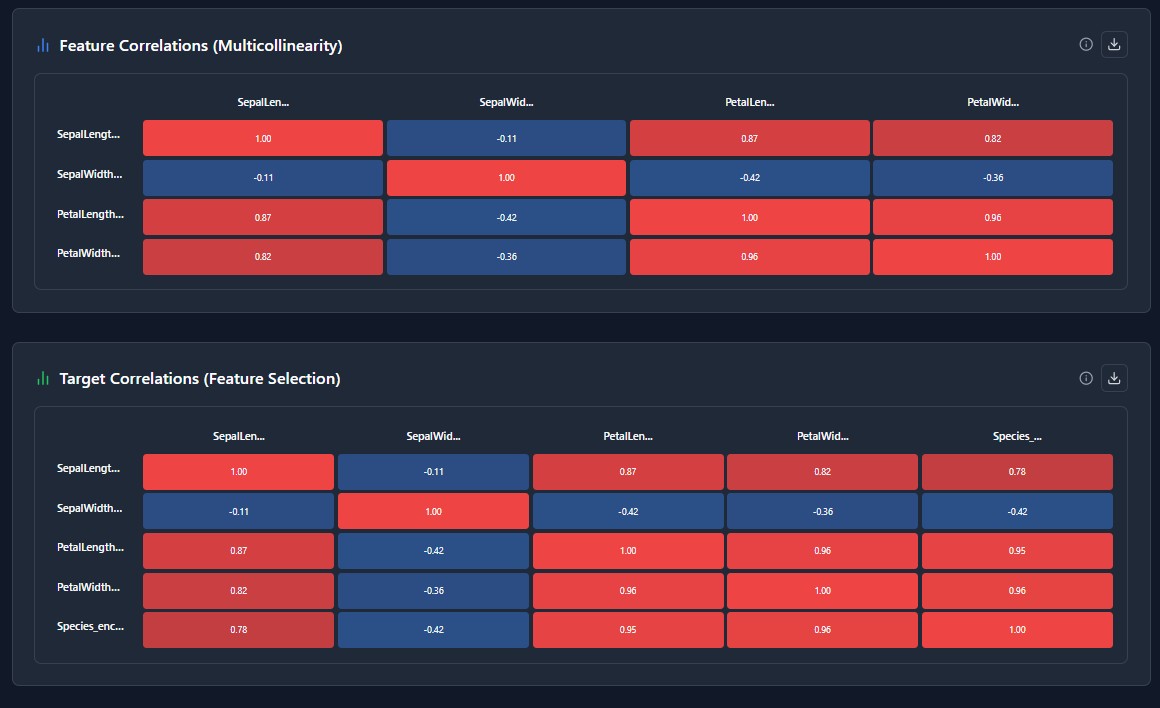
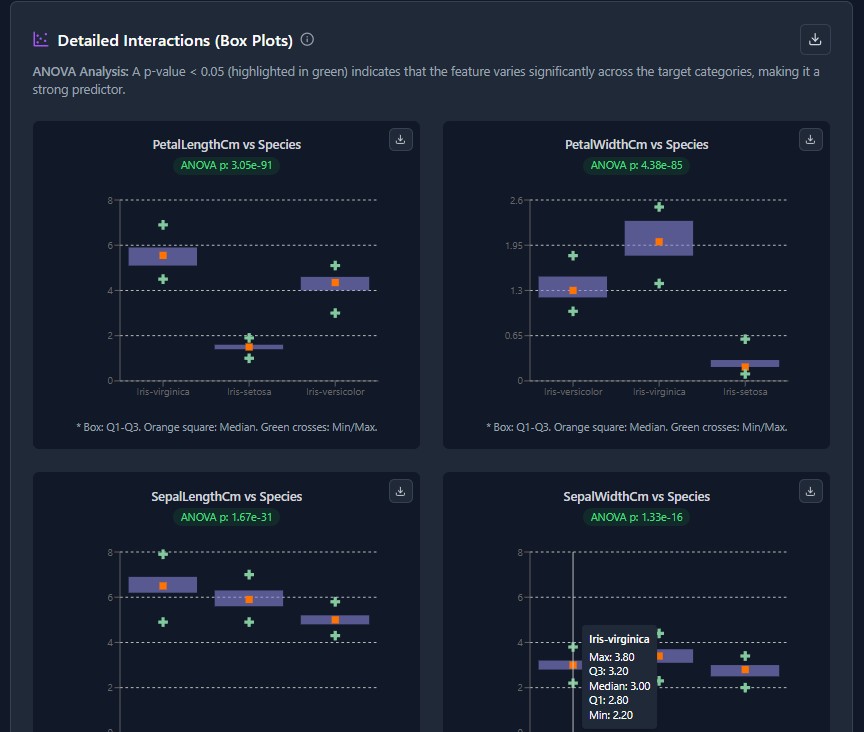
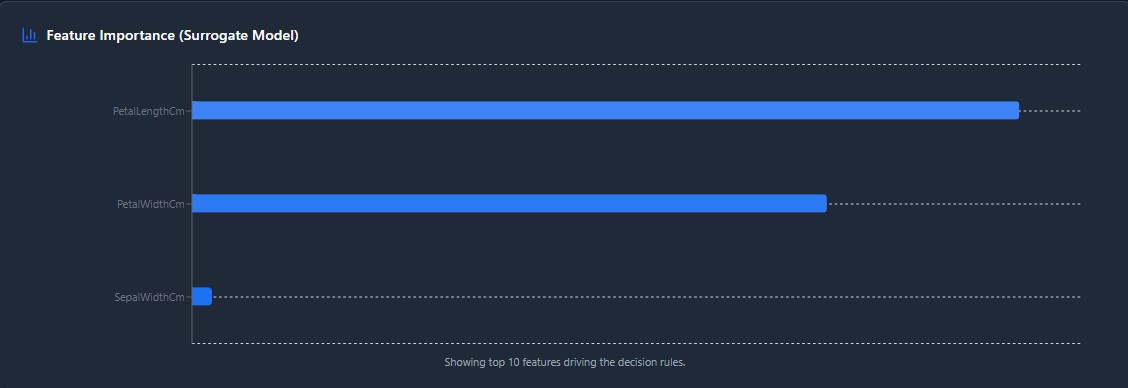
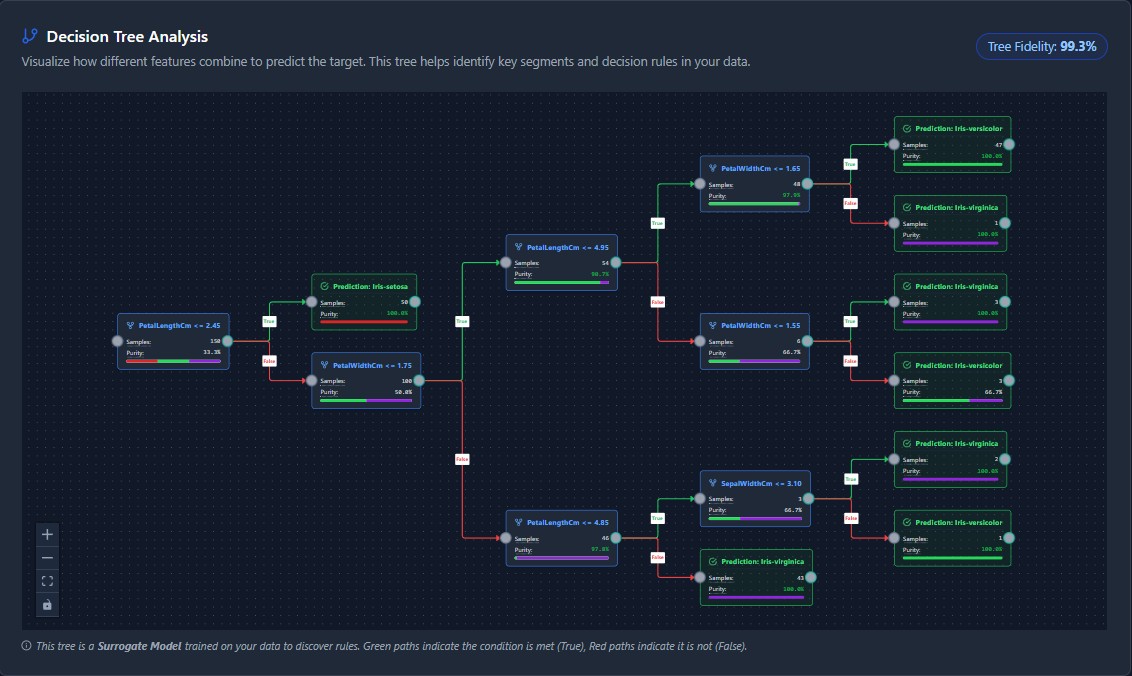
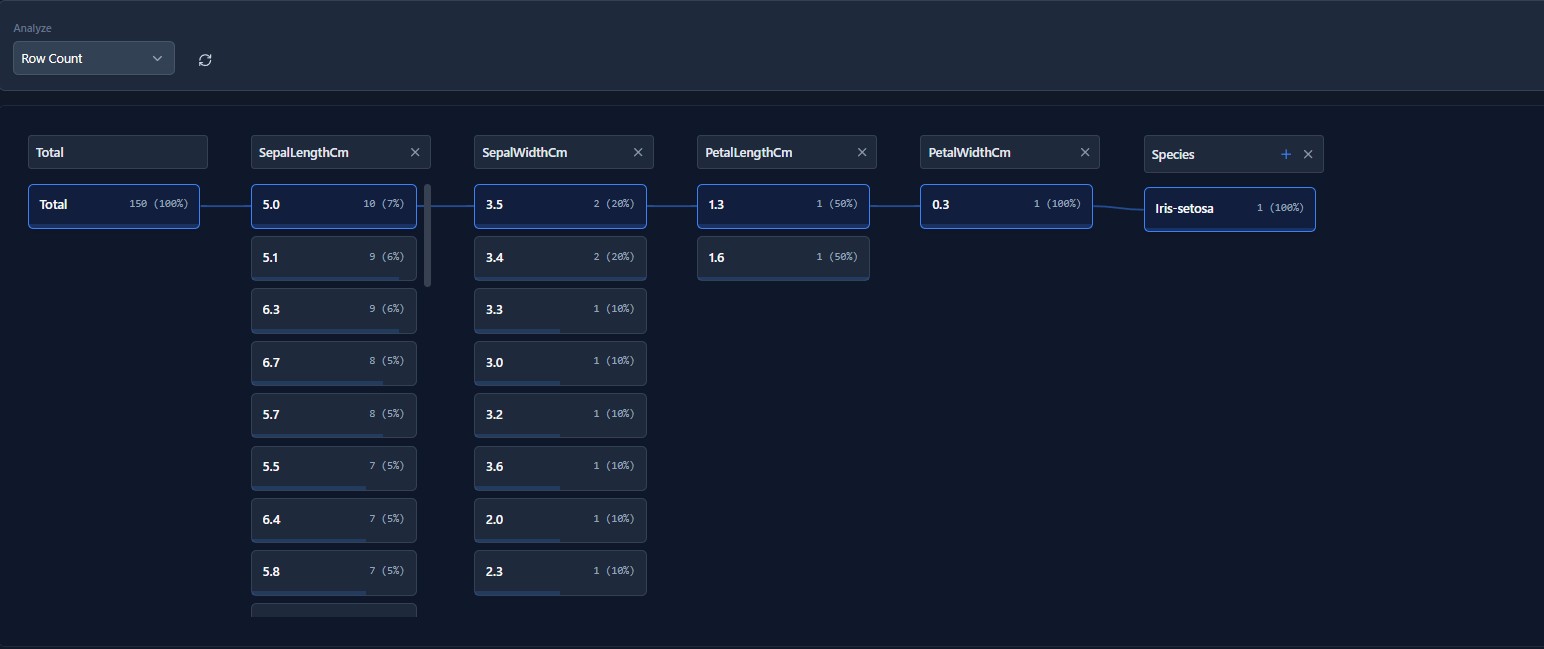
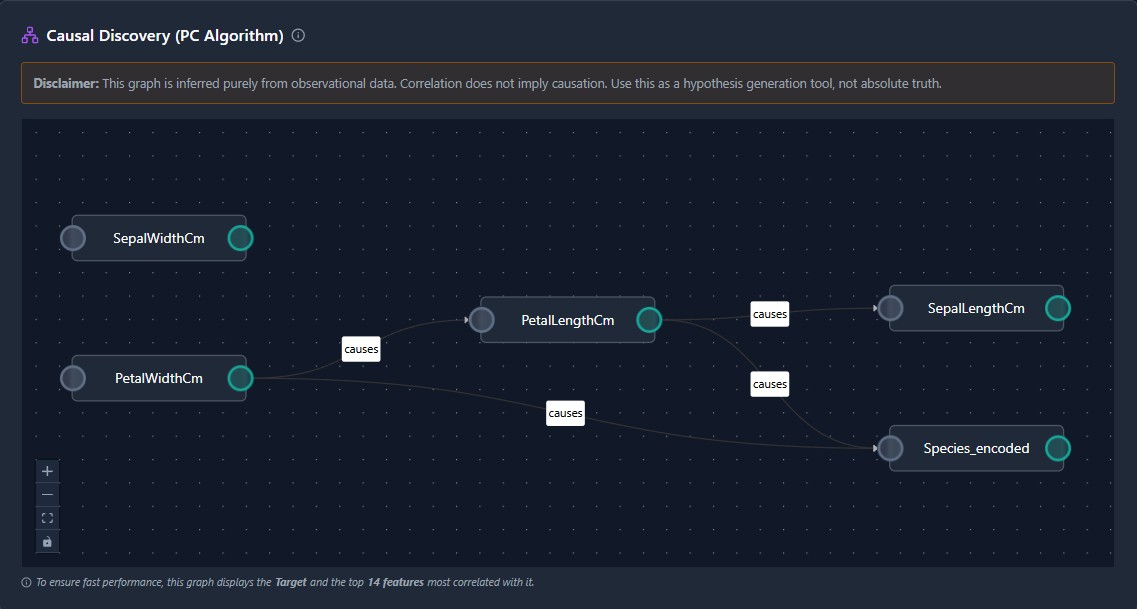
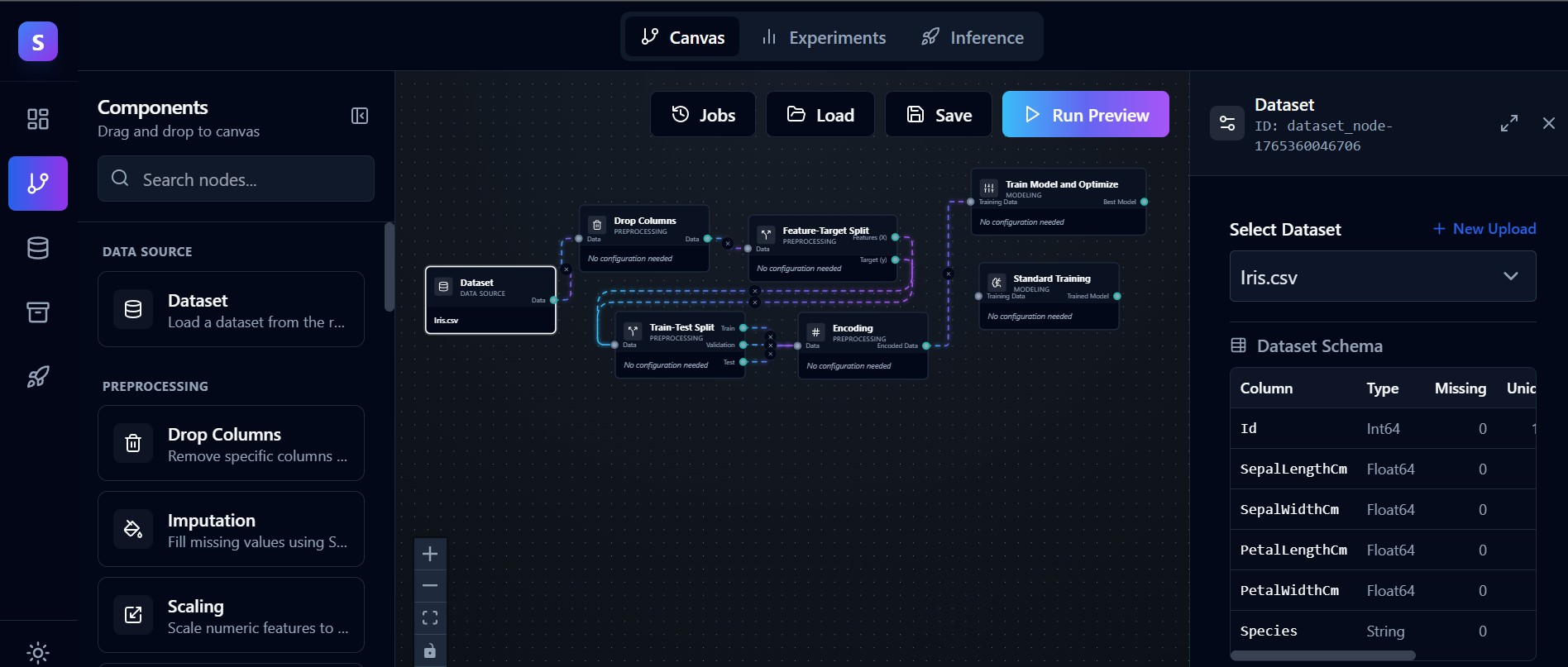
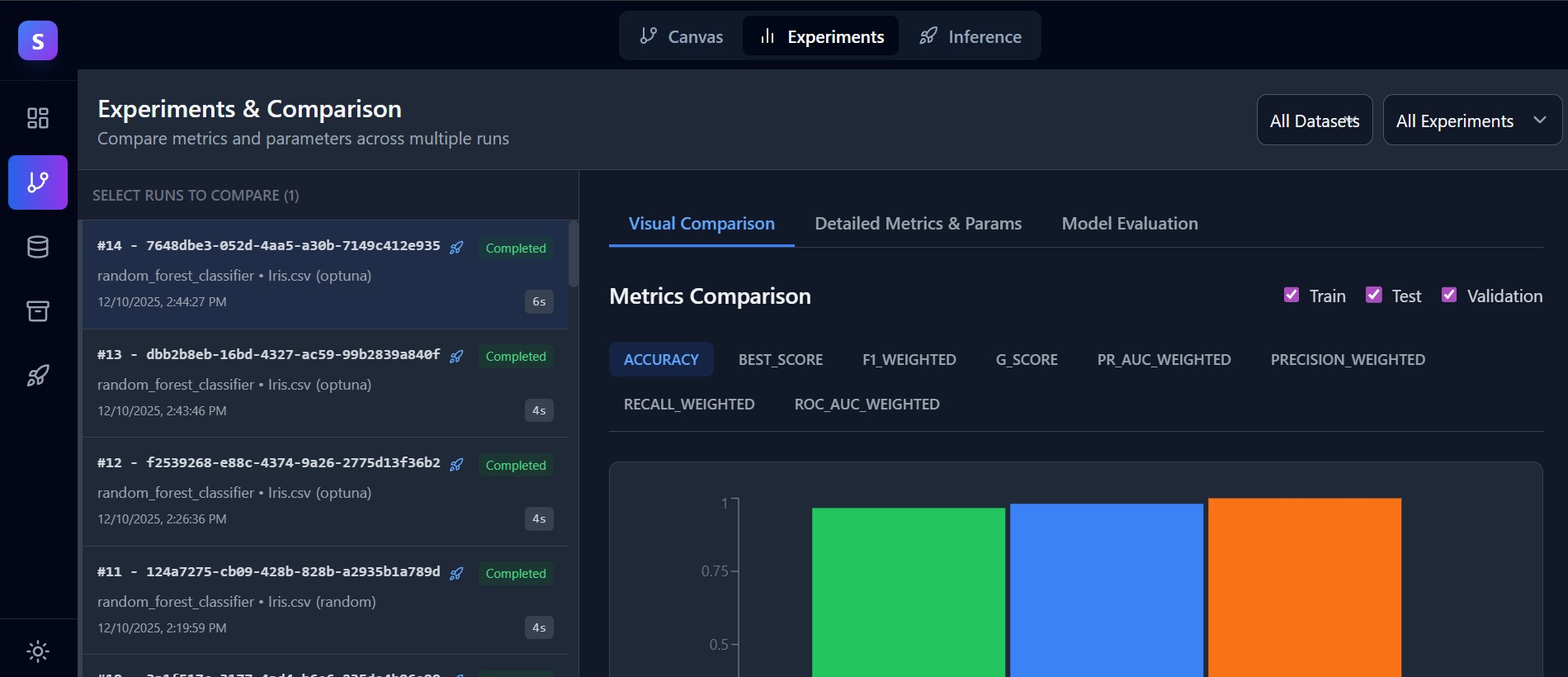
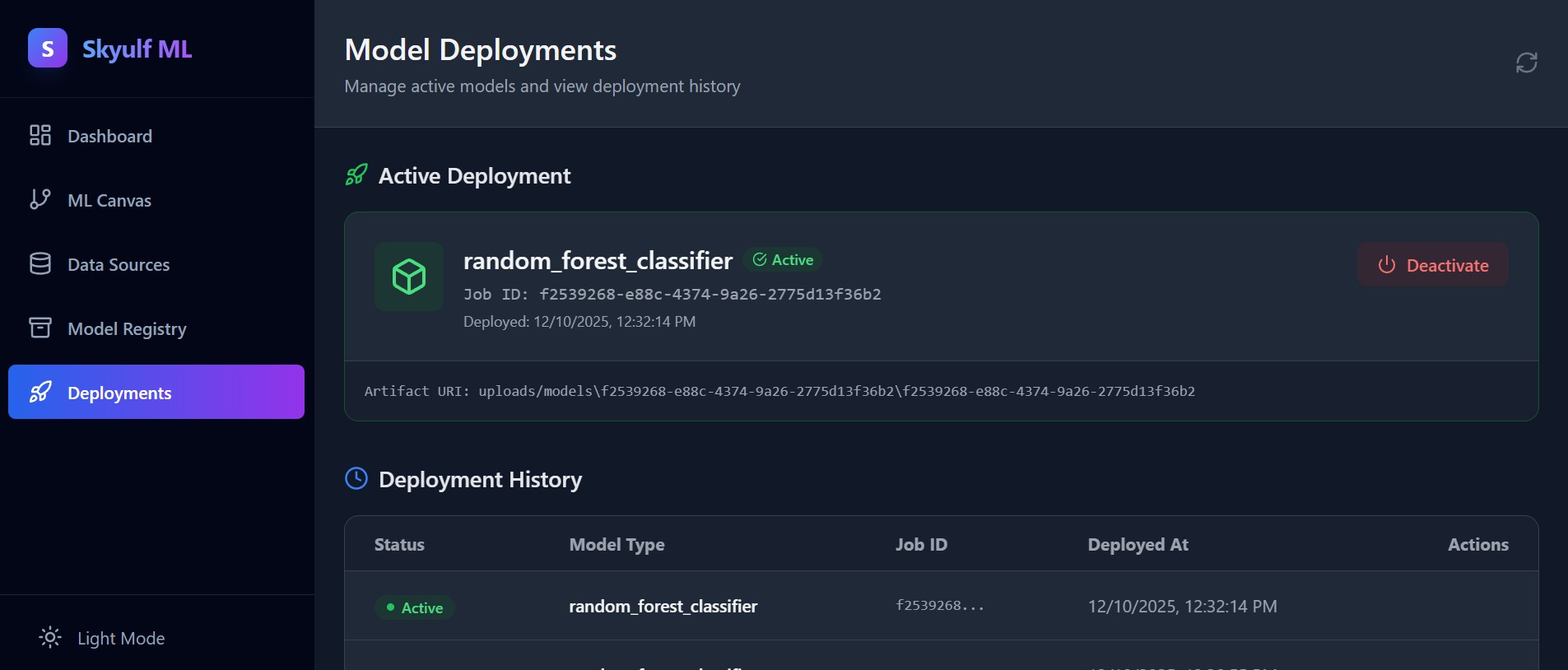
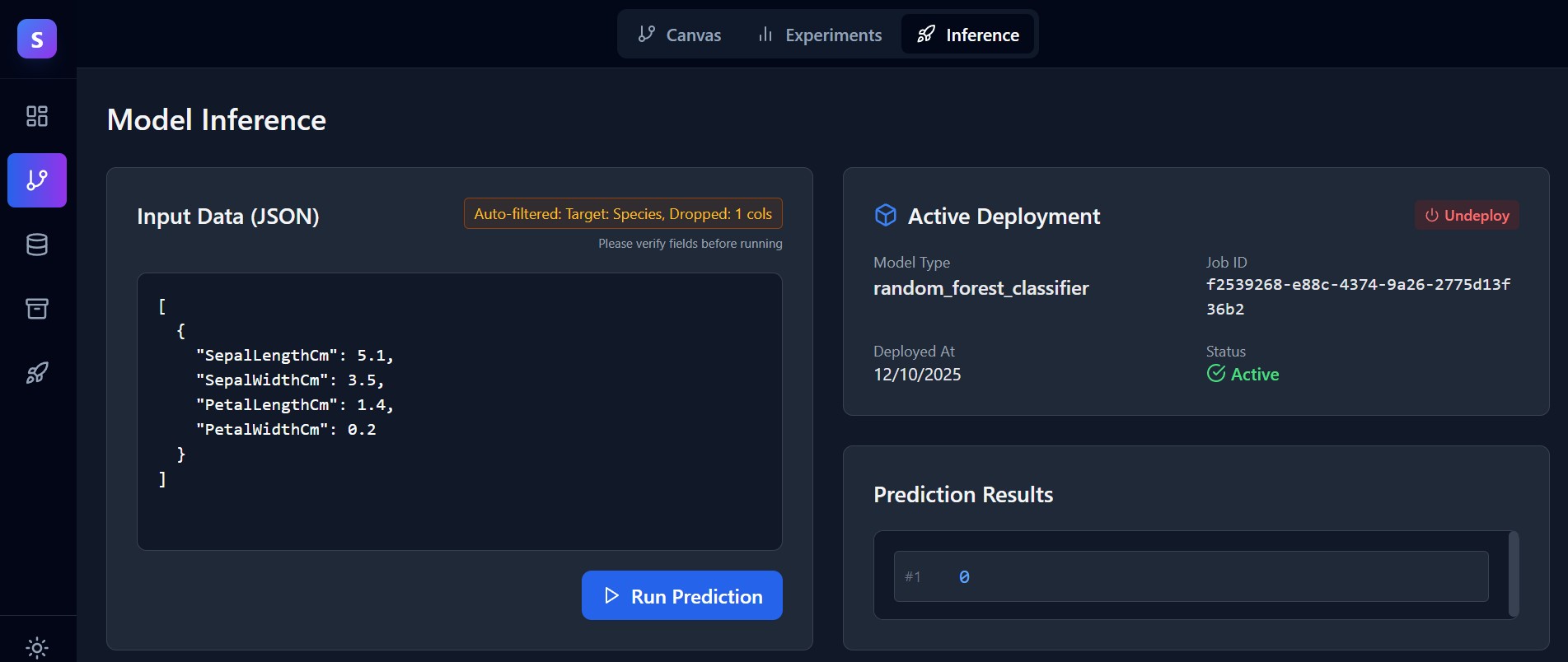
Own Your
ML Pipeline Locally
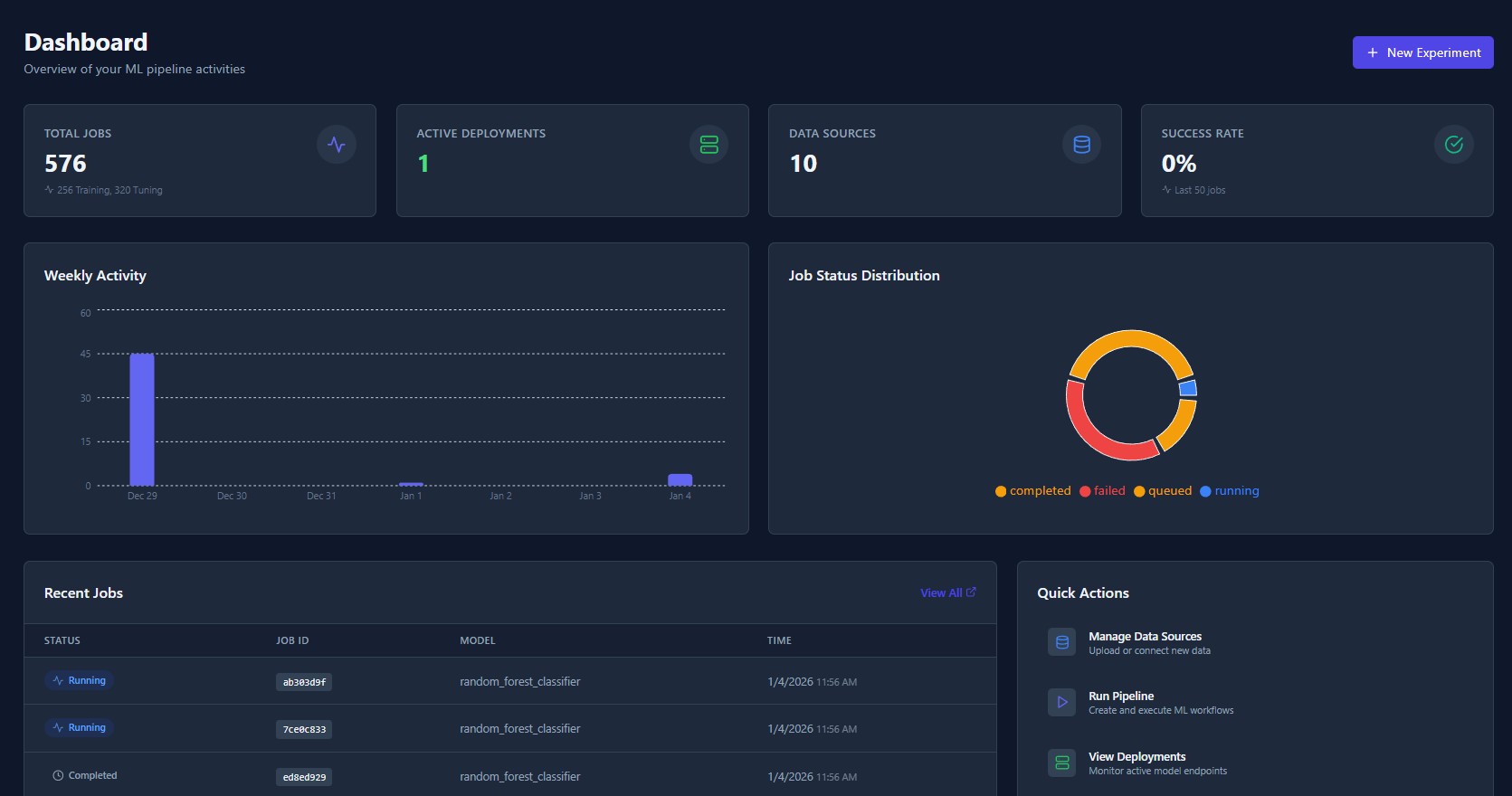
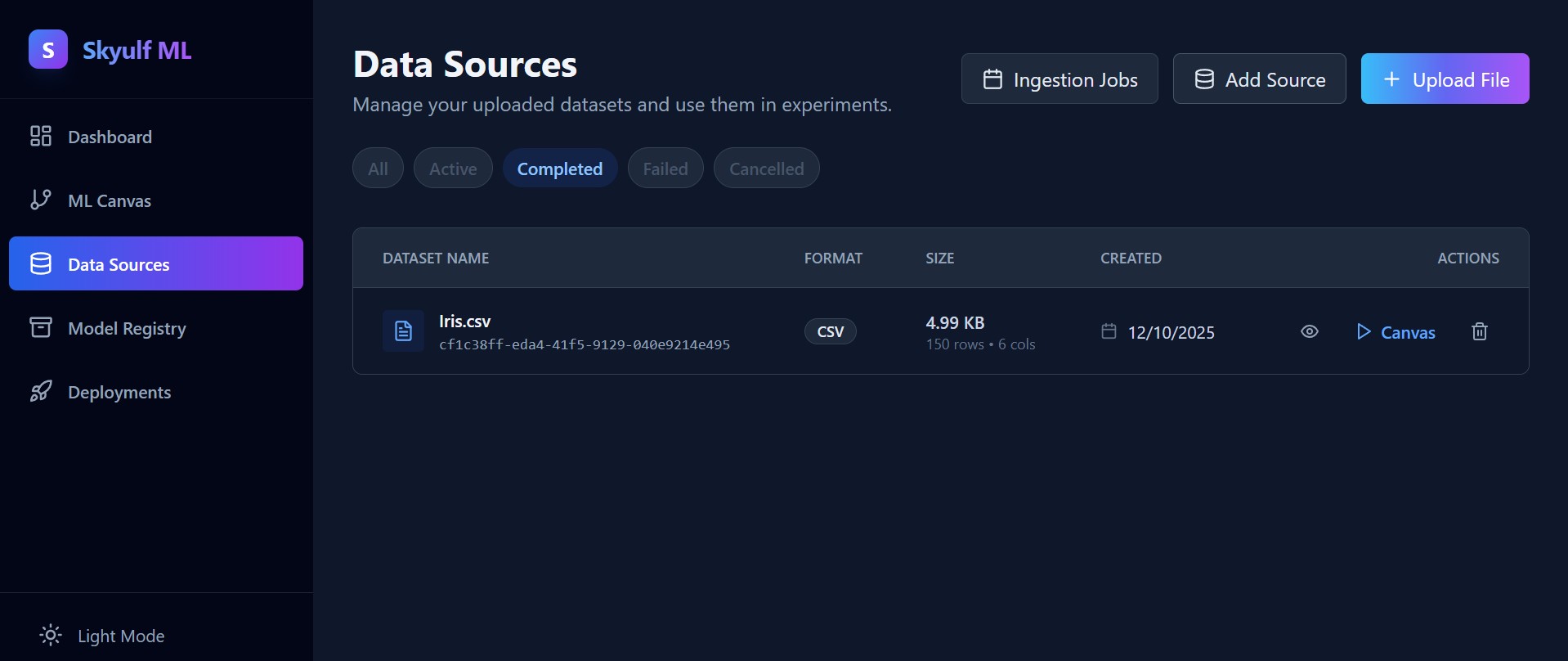
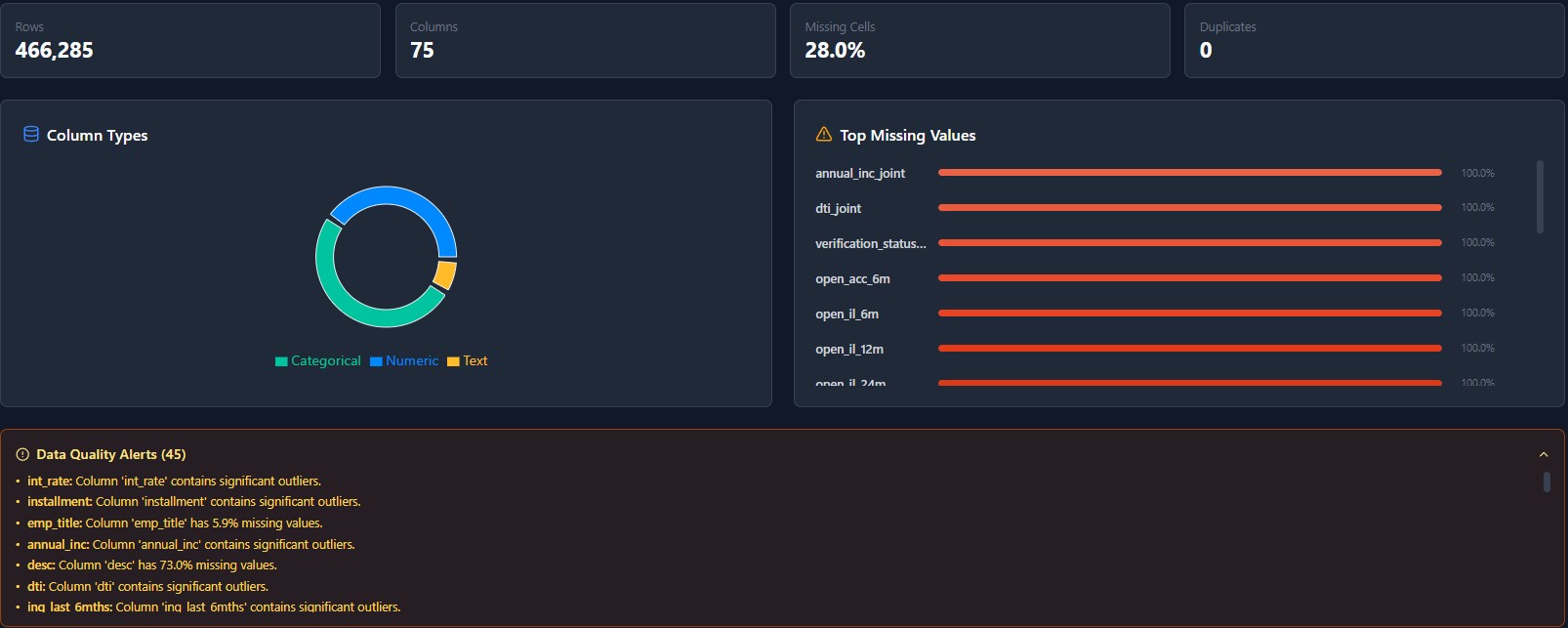
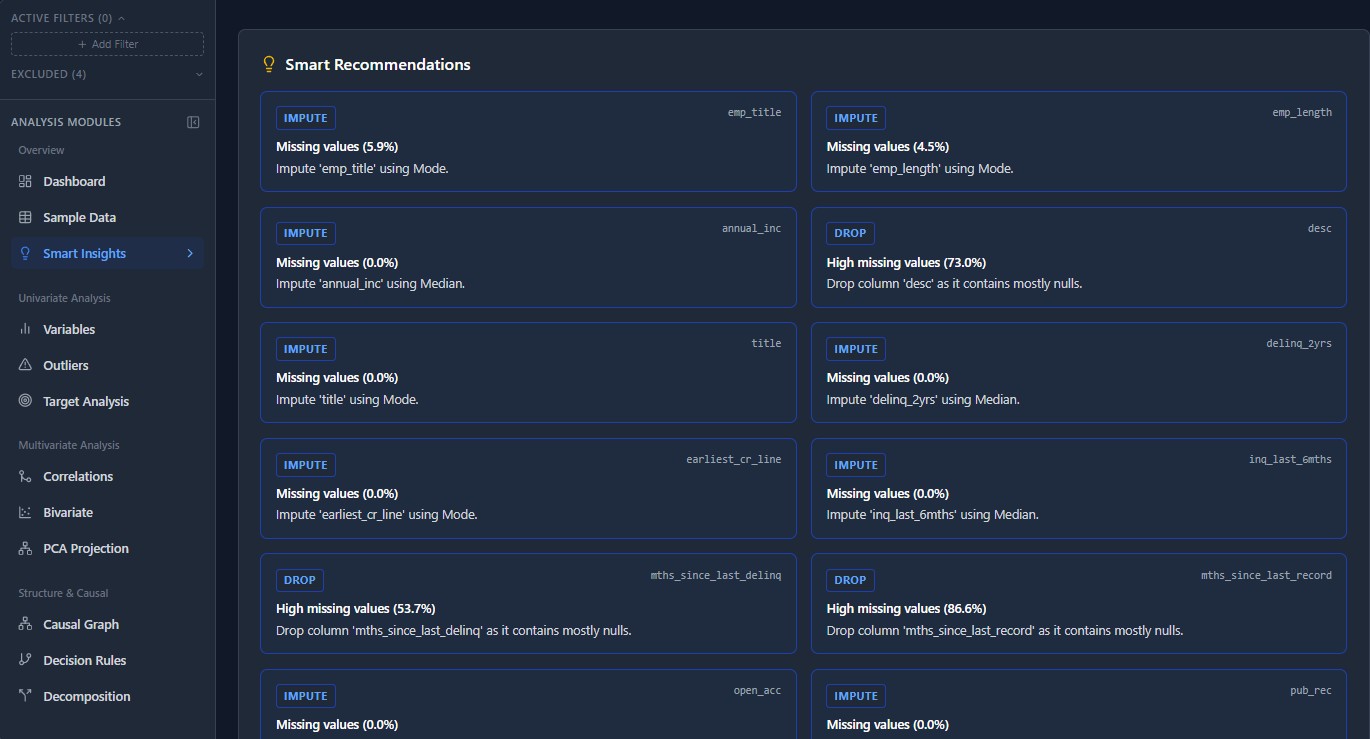
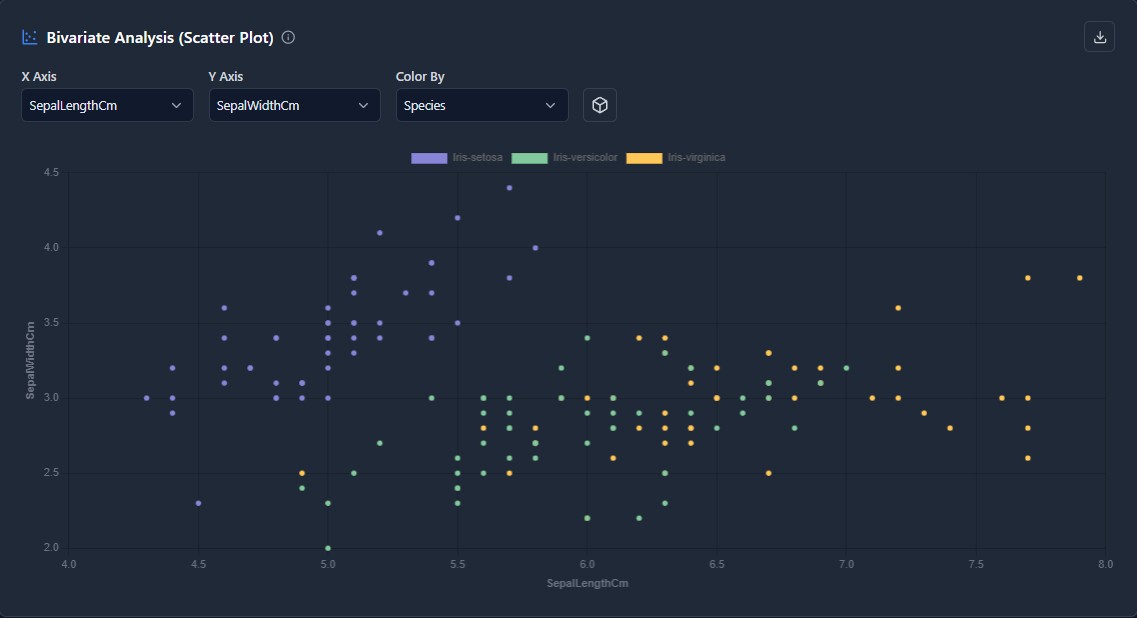
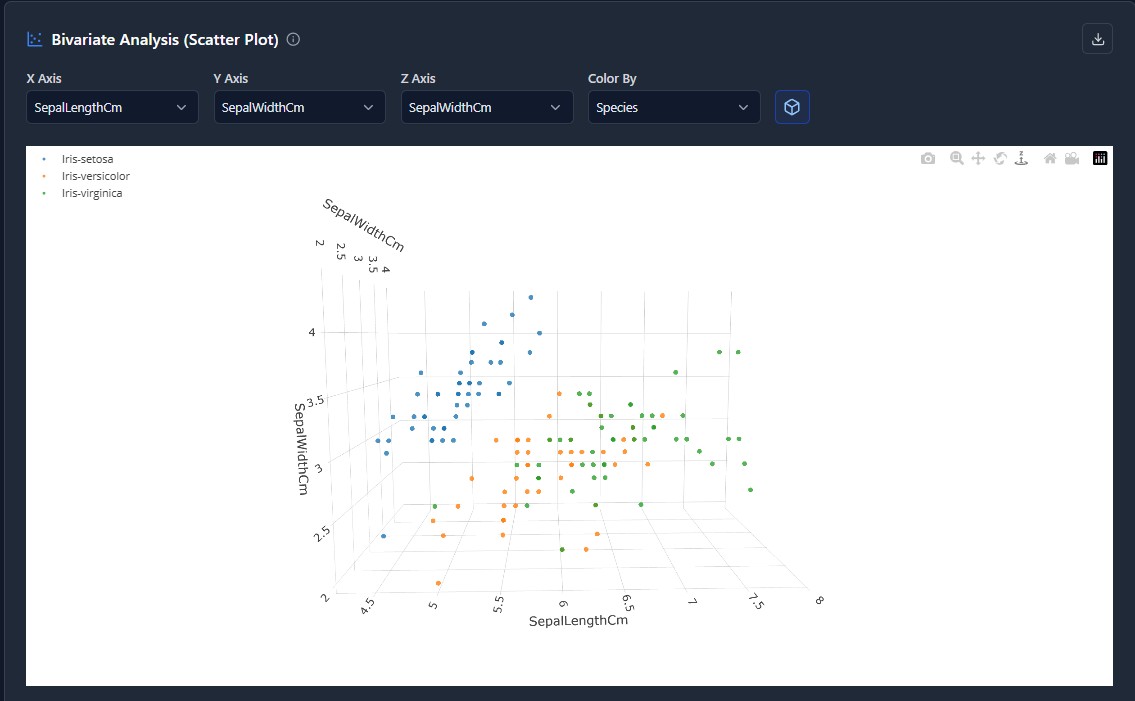
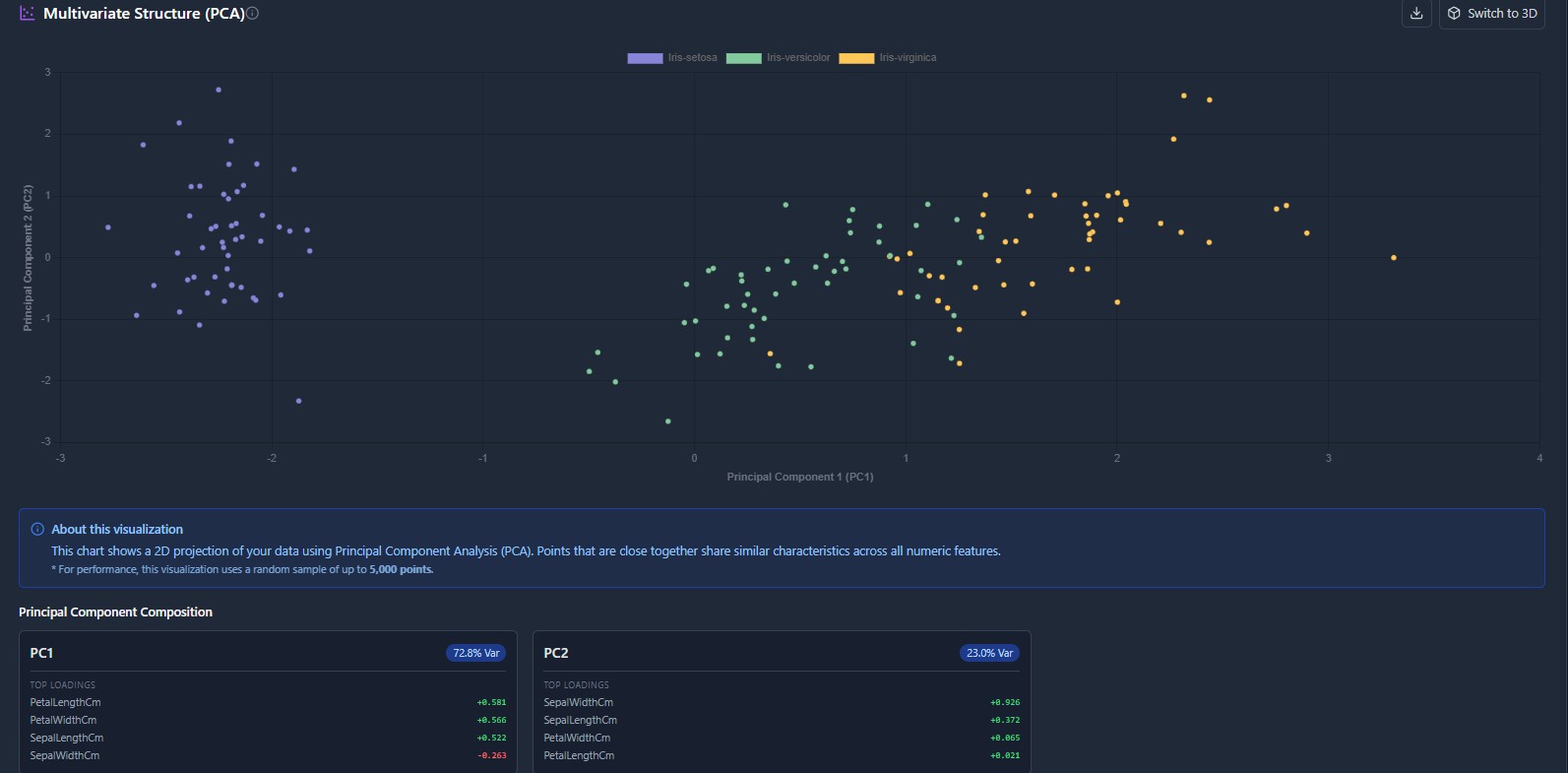
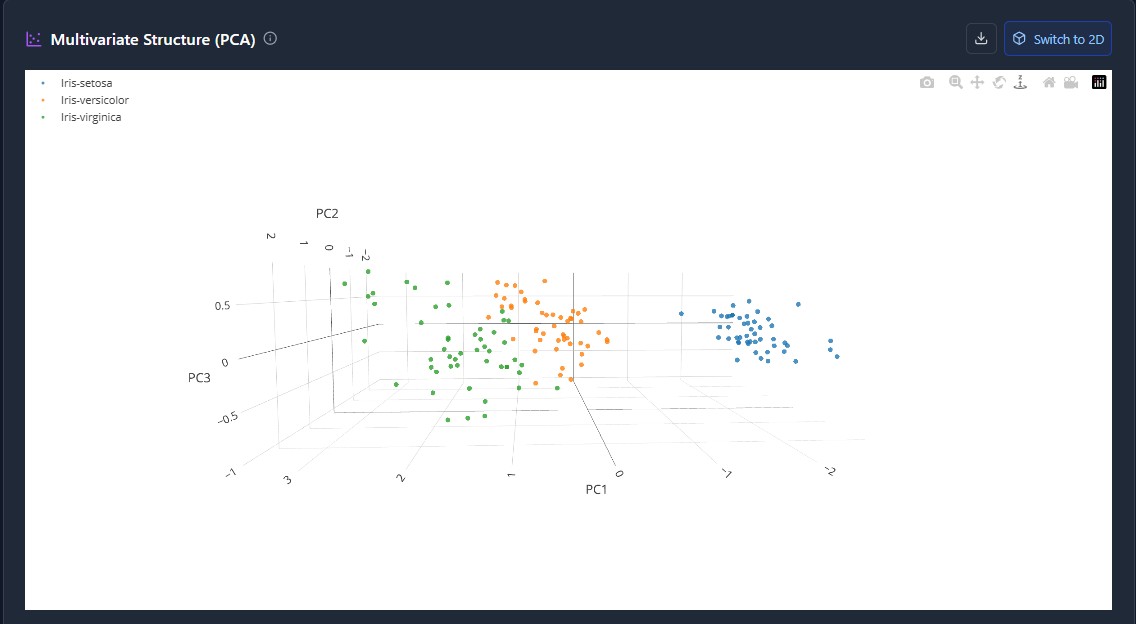
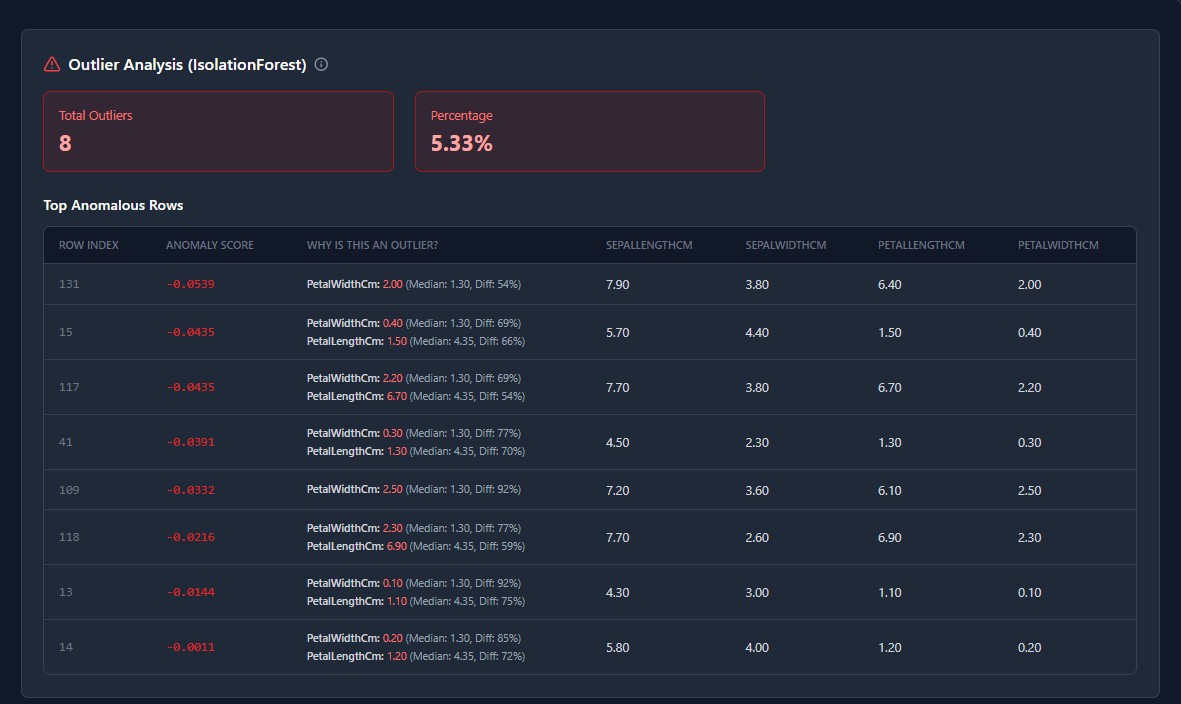
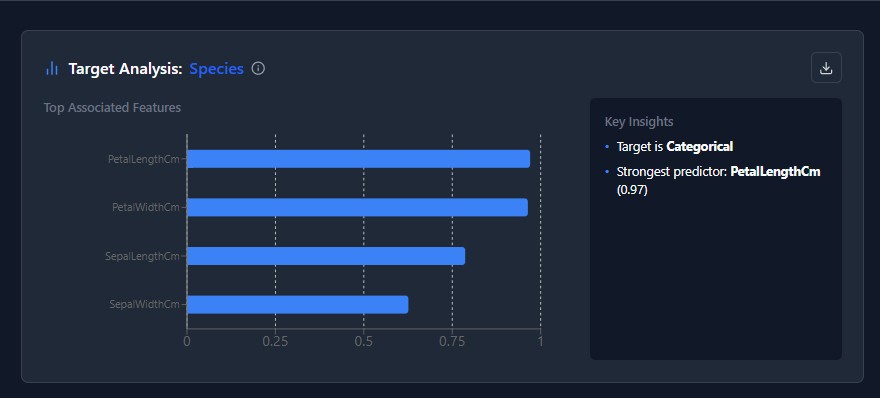
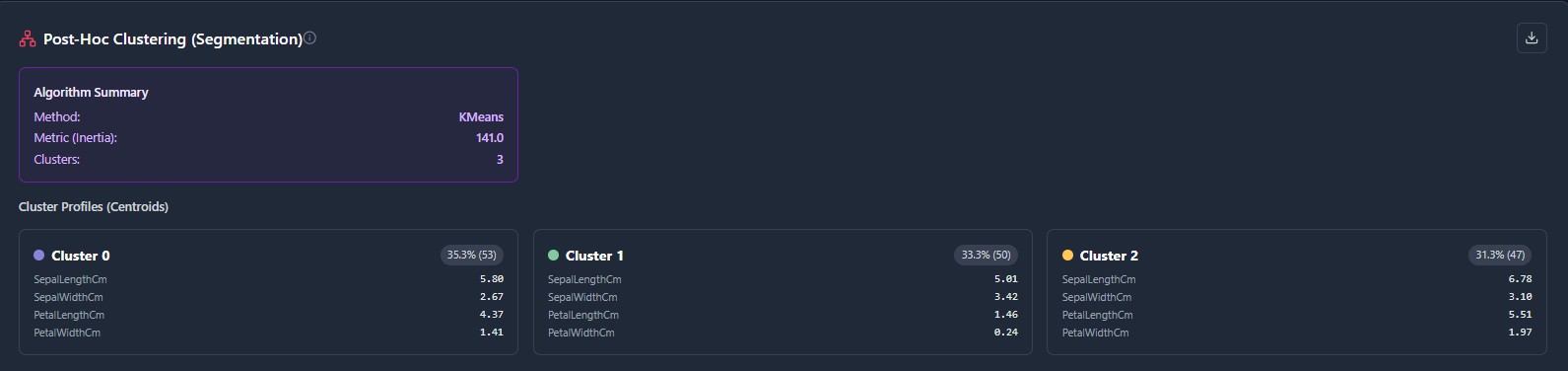
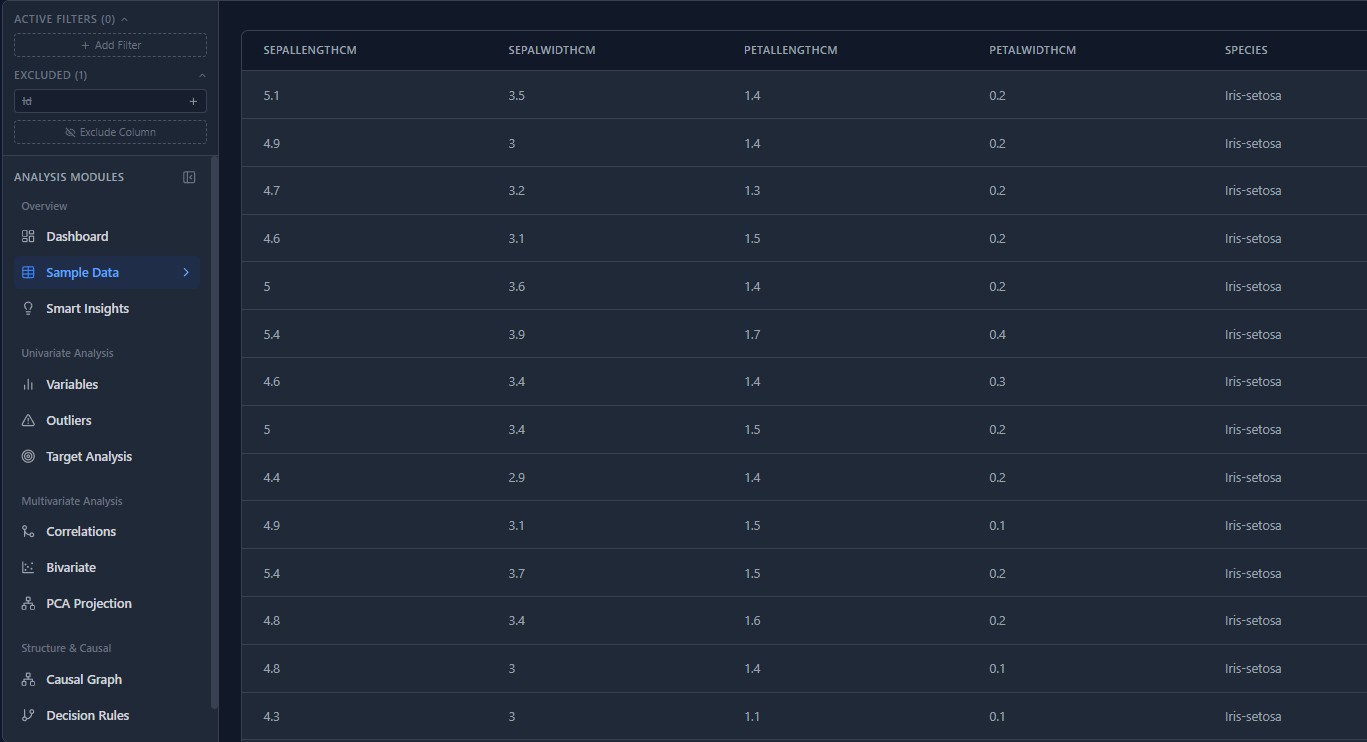
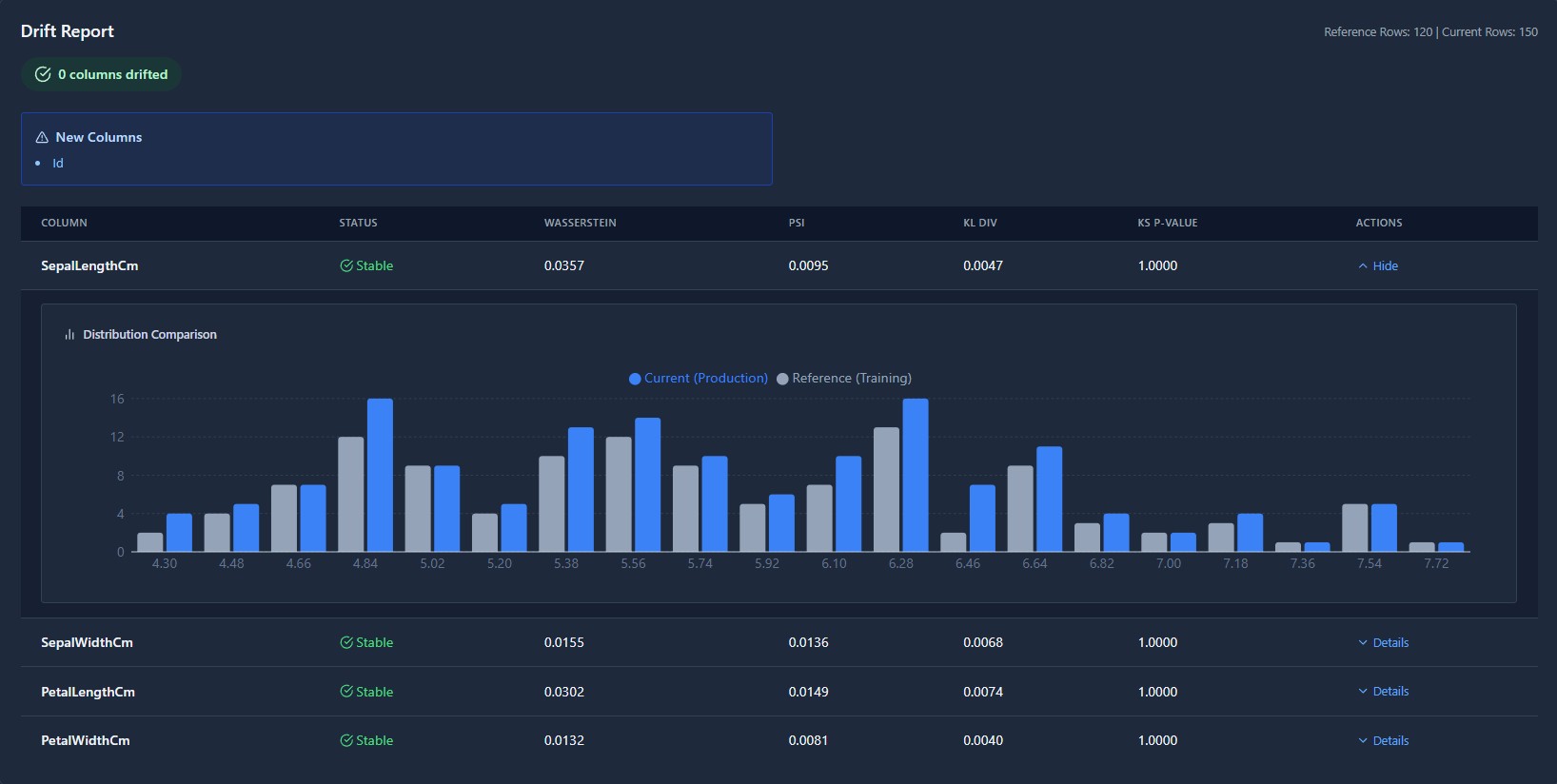
The privacy-first MLOps workspace. Ingest data, engineer features visually, and train models without your data ever leaving your infrastructure.